This post is part of the Fantastic F# Advent Calendar 2021 that has become a Christmas tradition over the years to bring the F# community together in celebration of the holiday season. A special thank you to our organizer, Sergey Tihon (@sergey_tihon) who is keeping this tradition vibrant and magical.
In this post we will leverage the .NET Channels to implement reusable and composable building block functions to define a concurrent workflow.
In this blogpost example, we are implementing a Pipeline to process a set of images read from the local filesystem. The idea is to create few reusable building blocks that use Channels as an underlying way to implement a high-performant procedures/consumers pattern, and then to use these building blocks to combine the image processing pipeline. In addition, we will apply a “pipeline” higher-order function to these building blocks, which shares the same output type, in order to ease the composition of multiple stages and the option to set a degree of parallelism.
You can download the code here
What are .NET Channels
.NET Channels is a static class that aims to provide high performant thread-safe data synchronization in a multithreaded program.
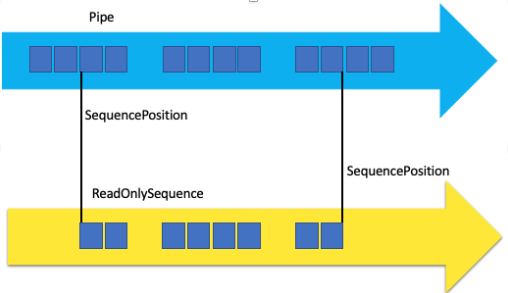
At the core, Channels supports shared data between producers and consumers in a concurrent fashion. Furthermore, Channels supports advanced producer and consumer patterns because one or many producers can write data into the channel, which are then read by one or many consumers. Logically a channel is effectively an efficient, thread-safe queue.
.NET Channels is a static class that exposes factory methods to create two main types of channels (bounded and unbounded).
(From Microsoft documentation)
CreateBounded<’a> creates a channel with a finite capacity. In this scenario, it’s possible to develop a producer/consumer pattern which accommodates this limit. We can use this type of Channel to store at most a specified number of items. The channel may be used concurrently by any number of reads and writers. Attempts to write to the channel when it contains the maximum allowed number of items results in behavior according to the mode specified when the channel is created, and can include waiting for space to be available, dropping the oldest item, or dropping the newest item. For example, you can have your producer (non-blocking) capacity within the channel before it completes its write operation. This is a form of backpressure; which, can slow your producer down, or even stop it until the consumer has read some items and created capacity.
In F# we can create a Bounded channel with a buffer of the items as follow:
let channel = Channel.CreateBounded<'a>(10)
CreateUnbounded<’a> creates a channel with an unlimited capacity, meaning that Publishers can publish as many times as they want, hoping that the Consumers are able to keep up. In this scenario, without a capacity limit, the channel will keep accepting new items. When the consumer is not keeping up, the number of queued items will continue to incresase. Each item being held in the channel requires memory which can’t be released until the object has been consumed. Therefore, in this scenario it’s possible to run out of available memory.
In F# we can create an Unbounded channel with unlimited buffer as follow:
let channel = Channel.CreateUnbounded<'a>()
Choosing the right Channel type is extremely important and highly depends on the context. Also, keep in mind that while it’s true that Unbounded Channels are indeed “unbounded”, the memory on the machine normally isn’t.
Channel and back-pressure
The term backpressure is borrowed from fluid dynamics and relates to the software systems dataflow. Backpressure occurs when a computer system can’t process the incoming data fast enough, so it starts to buffer the arriving data until the space to buffer it is reduced to the point of deteriorating the responsiveness of the system or, worse, raising an “Out of Memory” exception.
When creating bounded Channels to prevent backpressure issues, we can provide bounded options in the constractor to apply different strategies such as:
Channel.CreateBounded<T>(new BoundedChannelOptions(capacity)
{
FullMode = BoundedChannelFullMode.Wait // Wait - Wait for space to be available in order to complete the operation.
BoundedChannelFullMode.DropOldest // Remove and ignore the oldest item in the channel in order to make room
BoundedChannelFullMode.DropWrite // Drop the item being written.
});
Reader and writer
A Channels I instance exposes two properties:
- A “Reader” readable channel that returns a ChannelReader<T>
- A “Writer” writable channel that returns a ChannelWriter<T>.
These properties, as the names suggest, provide a set of methods (everything is done) to either write into the Channels or to read from:
- TryRead/TryWrite: Attempt to read or write an item synchronously, returning whether the read or write was successful.
- ReadAsync/WriteAsync: Read or write an item asynchronously. These will complete synchronously if data/space is already available.
- TryComplete/Completion: Channels may be completed, such that no additional items may be written; such channels will “complete” when marked as completed and all existing data in the channel has been consumed. Channels may also be marked as faulted by passing an optional Exception to Complete; this exception will emerge when awaiting on the Completion Task, as well as when trying to ReadAsync from an empty completed collection.
- WaitToReadAsync/WaitToWriteAsync: Return a Task<bool> that will complete when reading or writing can be attempted. If the task completes with a true result, at that moment the channel was available for reading or writing, though because these channels may be used concurrently, it’s possible the status changed the moment after the operation completed. If the task completes with a false result, the channel has been completed and will not be able to satisfy a read or write.
Why Channels
.NET Channels offers performance advantages when used to implement a producer consumer pattern when compared to other approaches such as TPL Dataflow and Concurrent Collections. In addition, the Channels asynchronous semantic provides a simple and straightforward way exploit and introduce high performant and thread-safe queue in any modern applications. Channels are a perfect fit when you need to have one or more dedicated threads for handling the queue.
In general, the producer consumer model can help improve the throughput of the application.
Another benefit of using Channels is to decouple producers and consumers, which has the advantage of generating independent producers and consumers from each other, that can be executed in parallel.
Producer/Consumer Pattern
Whenever using programs with any multi-step workflow, consideration must be given to some sort of producer and consumer pattern, which is commonly running serially. In almost every software we write there is a pipeline to achieve, where once a step is completed, then the output is passed to the next step in line, freeing up space for another execution. This pattern is based on the concept that every step in the series must be executed in total isolation, receiving data, processing it, and then pass it over to the next block. Consequently, every block should execute in its own thread, to guarantee the appropriate isolation and encapsulation.The producer and consumer patterns can be implemented in different topologies:
- one Producer and one Consumer
- one Producer and multiple Consumers
- multiple Producers and one Consumers
- multiple Producers and multiple Consumers
Here us a simple implementation of a producer/consumer pattern using channel. From this case we are expanding a more advanced case later in this blog.
let channel = Channel.CreateUnbounded<int>()
let producer () = task {
for item in [0..100] do
do! channel.Writer.WriteAsync(item)
channel.Writer.Complete()
}
let consumer () = task {
do!
channel.Reader.ReadAllAsync()
|> forEachAsync (fun item -> task {
printfn $"Received item %d{item}"
})
}
let runProducerConsumer () =
let producerTask = Task.Run(Func<Task>( producer ))
let consumerTask = Task.Run(Func<Task>( consumer ))
Task.WhenAll([producerTask; consumerTask])
In the code, after having initialized a “channel”, the function “producer” that generates the data items sent (or written into) the Channel Writer. Then we notify the channel that the data items generation is completed with the “Writer.Complete()” call. Next, the method “consumer” ingests the data items from the “Channel Reader” to produce a console output. The “Channel Reader” exposes the “ReadAllAsync” method, which allows to read from the channel Asynchronously through the interface “IAsyncEnumerable”. In F#, to support this interface we implement a helper function “forEachAsync”:
let forEachAsync (f: 'a -> Task<unit>) (asyncEn: IAsyncEnumerable<'a>) =
task {
let mutable canMoveNext = true
let enumerator = asyncEn.GetAsyncEnumerator()
while canMoveNext do
let! next = enumerator.MoveNextAsync()
canMoveNext <- next
if canMoveNext then
do! f enumerator.Current } :> Task
In this implementation of the function “forEachAsync”, we assume an ad-hoc case where the output of the AsyncEnumerble stream is either passed into a Channel or produces a side effect that returns “unit”.
The last method “runProducerConsumer” executes concurrently the previous methods each spawned in a different Task.
.NET Channels helps us deal with these scenarios efficiently by guarantying those producers and consumers, implemented in any shapes, can handle their own tasks without interfering with each other, which is conducive to the concurrent processing of both sides.
Pipelines and Producer/Consumer
In many scenarios, we can create a workflow from the combination of two or more producer/consumer steps, each step performing a different job. This pattern is commonly called pipeline. A pipeline is a concurrency model where a work is performed and moved through several processing stages. Each step performs a part of the complete work, and when it’s completed, the output is passed to the following next stage. In addition, each stage of the pipeline runs in a separate thread, and it does not share any state with the other stages.
Implementing a pipeline using channels
In general, a pipeline begins with a producer method, which starts a process to generate some data that is passed to the first stage of the pipeline, and then the output is moved through the stages. The intermediate stages are executed concurrently. In this case, the Channel operates as a transport mechanism between the stages. The design of a concurrent Pipeline using Channels is composed by stages that take a “Reader Channel” as an input, executes work on each data item asynchronously, and then transfers the result into an “Writer Channel”.
From the previous producer/consumer implementation using .NET Channels, we can extract a reusable function to behave as base building block to define a workflow. Here is the code implementation:
let pipeline (cTok: CancellationToken) (projection: 'a -> Task<'b>) (reader: ChannelReader<'a>) =
let pipe = Channel.CreateBounded<'b>(10)
let writer = pipe.Writer
let _ = Task.Run(Func<Task>(fun () -> castTask <| task {
do!
reader.ReadAllAsync(cTok)
|> forEachAsync (fun item -> task {
let! outputItem = projection item
do! writer.WriteAsync(outputItem)
}) cTok
writer.Complete()
}
)
)
pipe.Reader
The function “pipeline” takes as input arguments:
- a cancellation-token, which can be used to stop the pipeline stages
- a projection function that transforms the data item input read from the ChannelReader<a’>
- a ChannelReader<a’> to read the data item
Internally, the “pipeline” function initializes a “bounded” channel (to keep the code simple we set the buffer to 10, but we can expand the function to set this value as needed). This channel is used to write into it asynchronously the output of the projection function. Then, this channel is returned from the function to be passed in other stages of the workflow to share the data for further processing.
The “pipeline” function runs the “consume and produce” logic into a dedicated Task to enable support for concurrency.
The same idea applies to the implementation of an action block, which produces the final side effect of the workflow.
let pipelineAction (cTok: CancellationToken) (action: 'a -> Task) (reader: ChannelReader<'a>) =
Task.Run(Func<Task>(fun () -> castTask <| task {
do!
reader.ReadAllAsync(cTok)
|> forEachAsync (fun item -> task {
do! action item
}) cTok
}
)
)
TPL Dataflow vs Channels
The System.Threading.Tasks.Channels library provides a set of synchronization data structures for passing data between producers and consumers. Whereas the existing System.Threading.Tasks.Dataflow library is focused on pipelining and connecting together dataflow “blocks” which encapsulate both storage and processing, System.Threading.Tasks.Channelsis focused purely on the storage aspect, with data structures used to provide the hand-offs between participants explicitly coded to use the storage. The library is designed to be used with async/await in C#.
Channel Broadcast
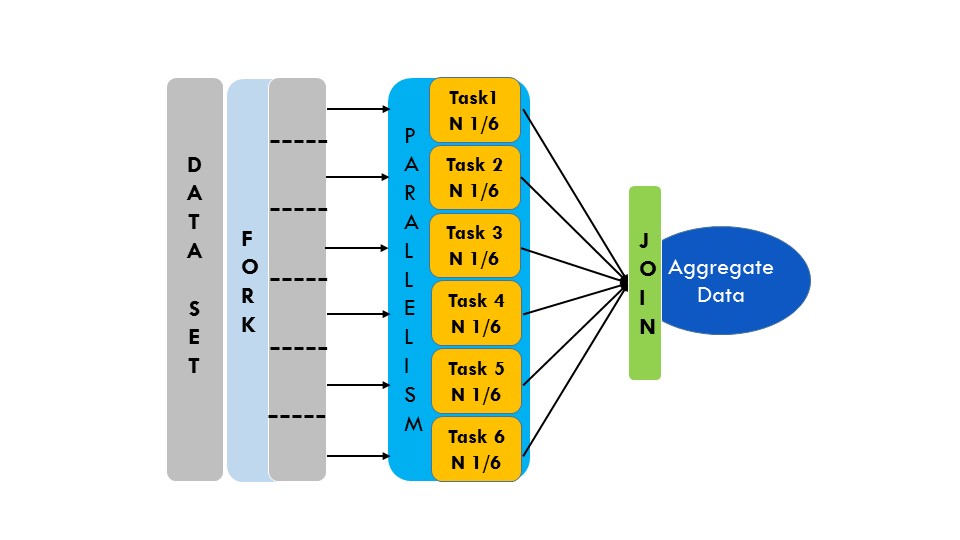
The idea of the Broadcast Channel stage is to provide a reusable function that takes as input a “Channel Reader”, which is used to read data from, and return a set of “Channel Readers” that transport a copy of the same data item. Each of those “Channel Readers” is then connected to a different stage of the pipeline allowing it to process the data concurrently. The Broadcast Channel is useful when dealing with work stages that can originate backpressure because the execution time to consume a data item is slower than the volume of the data items produced by the previous step in the pipeline. Leveraging the Broadcast stage, we can distribute the workload among concurrent stages increasing the capacity of the slow stage to cope with a large volume of data to process. The Broadcast Channel stage takes an input channel and distributes its messages amongst several outputs. The Broadcast stage runs concurrently and in a non-blocking fashion.
Here the code implementation:
let broadcast (cTok: CancellationToken) n (channel: ChannelReader<'a>) =
let outputs = Array.init n (fun i -> Channel.CreateUnbounded<'a>())
let _ = Task.Run(Func<Task>(fun () -> castTask <| task {
do!
channel.ReadAllAsync(cTok)
|> forEachAsync (fun item -> task {
for output in outputs do
do! output.Writer.WriteAsync(item, cTok)
}) cTok
for output in outputs do output.Writer.Complete()
}))
outputs |> Array.map(fun ch -> ch.Reader)
The “broadcast” function takes as input arguments :
- a cancellation-token, which can be used to stop the pipeline stages
- an arbitrary number that defines the count of new channels to initialize for the data sharing
- a ChannelReader<a’> to read the data item from
When this block runs, a set of “n” new channels is initialized and used to forward the data items read from the channel reader. With this design, each new channel receive a copy of the same data item. Then, the function “broadcast” returns the newly created set of channels to distribute the work among other channels, and possibly to different branches of the workflow. This broadcast” function is useful to increase the degree of parallelism in our pipeline implementation.
Channel Join
The same concept used to implement to Broadcast Channel applies in reverse, where we join a set of “Reader Channels” into a single “Reader Channel” stream. In this way, we can implement a Join stage to read concurrently data items from two or more stages by combining their outputs into a single “Reader Channel”.
Here the code implementation, which is the reverse of the previous “broadcast” function:
let join (cTok: CancellationToken) (inputs: ChannelReader<'a> array) =
let output = Channel.CreateUnbounded<'a>()
let writeAsync (input: ChannelReader<'a>) =
task {
do!
input.ReadAllAsync(cTok)
|> forEachAsync (fun item -> task {
do! output.Writer.WriteAsync(item)
}) cTok
} :> Task
let _ = Task.Run(Func<Task>(fun () -> castTask <| task {
do!
inputs
|> Array.map writeAsync
|> Task.WhenAll
output.Writer.Complete()
}))
output.Reader
In this implementation, a collection of “Reader Channels” is passed as input into the “join” function, which begins to read data items concurrently and directly passed into a local new single Channel which fuses the outputs from the input channels. The Join stage runs concurrently and in a non-blocking fashion.
Code implementation details
We have created few reusable building blocks:
- the “pipeline” block, which helps to create and easily compose the workflow stages
- the “broadcast” block, from the TPL Dataflow Broadcast block idea, which enables you to dispatch a copy of the same data item across other stages and/or increase the degree of parallelism of a give stage
- the “join” block, from the TPL Dataflow Join block idea, which allows you to fuse together into a single channel the output of a set of give channels
With the help of these building blocks, we can define our workflow for the image processing. For this blogpost, we implement three variants of this pipeline:
- Sequential Pipeline, which is the simplest implementation of the image processing workflow composing the stages using the “pipeline” function
- ForkJoin Pipeline, which expands the Sequential Pipeline with the exploit of the “Broadcast” and “Join” functions to improve the performance of the pipeline
- Multi ForkJoin Pipeline, which expands the ForkJoin Pipeline design to support multiple workflow branches
The initial Step. Generate the data
The initial stage of our pipeline generates the data items, which are the begining of the workflow. This stage reads the image files from a give folder, and sends the file read to the next stage of the pipeline functioning as producer.
let dataGenerator sourceImages (cTok: CancellationToken) : ChannelReader<string> =
let images = Directory.GetFiles(sourceImages, "*.jpg")
let channel = Channel.CreateBounded<string>(10)
let rnd = Random()
let _ = Task.Run(Func<Task>(fun () -> castTask <| task {
do!
images
|> Seq.map (fun image ->
task {
do! channel.Writer.WriteAsync(image, cTok)
do! Task.Delay(TimeSpan.FromSeconds(float(rnd.Next(3))))
}
:> Task)
|> Task.WhenAll
channel.Writer.Complete()
}), cancellationToken = cTok
)
channel.Reader
The next step is loading the images from the filesystem to create a record type ImageInfo, which is used to keep details of the image file, and ultimately it passes the output to a Channel that is returned from this function and ready to be passed to the next stage of the pipeline functioning as producer.
The next steps follow the same pattern, therefore I left out the repetition of the same code details.
The Sequential Pipeline
Here is the code implementation of the Sequential Pipeline:
let executeSequential (source: string) destination = task {
if Directory.Exists destination |> not then
Directory.CreateDirectory destination |> ignore
let cTok = new CancellationTokenSource()
let pipelineCtok f = pipeline cTok.Token f
do!
dataGenerator source cTok.Token
|> pipelineCtok (fun path -> task {
let! image = ImageProcessingHelpers.loadImageAsync path
let outputItem =
{
name = Path.GetFileName(path)
source = path
destination = destination
image = image
}
return outputItem
})
|> pipelineCtok (fun imageInfo -> ImageProcessingHelpers.scaleImage imageInfo)
|> pipelineCtok (fun imageInfo -> ImageProcessingHelpers.convertTo3D imageInfo)
|> pipelineAction cTok.Token (fun imageInfo -> ImageProcessingHelpers.saveImage imageInfo)
}
In the code creating the different steps of the workflow:
- loadImageAsync
- scaleImage
- convertTo3D
- saveImage
Then we composed them together using the “pipeline” function. The last step of the pipeline uses “pipelineAction” function to save each the image processed.
The ForkJoin Pipeline
Here the code implementation of the ForkJion Pipeline:
let executeForkJoin (source: string) destination = task {
if Directory.Exists destination |> not then
Directory.CreateDirectory destination |> ignore
let cTok = new CancellationTokenSource()
let pipelineCtok f = pipeline cTok.Token f
let broadcast = broadcast cTok.Token 4 (dataGenerator source cTok.Token)
let pipe reader =
reader
|> pipelineCtok (fun path -> task {
let! image = ImageProcessingHelpers.loadImageAsync path
let outputItem =
{
name = Path.GetFileName(path)
source = path
destination = destination
image = image
}
return outputItem
})
|> pipelineCtok (fun imageInfo -> ImageProcessingHelpers.scaleImage imageInfo)
|> pipelineCtok (fun imageInfo -> ImageProcessingHelpers.convertTo3D imageInfo)
do!
broadcast
|> Array.map pipe
|> join cTok.Token
|> pipelineAction cTok.Token (fun imageInfo -> ImageProcessingHelpers.saveImage imageInfo)
}
In this code implementation, we are expanding the Sequential Pipeline to run concurrently in four different tasks using the broadcast function, which aims to improve the performance because we can process four images simultaneously. Ultimately, we are combining the Channel outputs into a single stream Channel to save the images as a last single step.
The Multi ForkJoin Pipeline
Here the code implementation of the MultiForkJion Pipeline:
let executeMultiForkJoin (source: string) destination = task {
if Directory.Exists destination |> not then
Directory.CreateDirectory destination |> ignore
let cTok = new CancellationTokenSource()
let pipelineCtok f = pipeline cTok.Token f
let pipe transform reader =
reader
|> pipelineCtok (fun path -> task {
let! image = ImageProcessingHelpers.loadImageAsync path
let outputItem =
{
name = Path.GetFileName(path)
source = path
destination = destination
image = image
}
return outputItem
})
|> pipelineCtok (fun imageInfo -> ImageProcessingHelpers.scaleImage imageInfo)
|> pipelineCtok (fun imageInfo -> transform imageInfo)
let pipe3D = pipe (fun imageInfo -> ImageProcessingHelpers.convertTo3D imageInfo)
let pipeRedFilter = pipe (fun imageInfo -> ImageProcessingHelpers.setFilter imageInfo ImageFilter.Red)
let pipeBlueFilter = pipe (fun imageInfo -> ImageProcessingHelpers.setFilter imageInfo ImageFilter.Blue)
let pipeGreenFilter = pipe (fun imageInfo -> ImageProcessingHelpers.setFilter imageInfo ImageFilter.Green)
let collapse (source: ChannelReader<'a>) (maps: (ChannelReader<'a> -> ChannelReader<'b>) array) =
let countBranches = maps |> Array.length
let sources = broadcast cTok.Token countBranches source //
Array.zip sources maps
|> Array.map (fun (reader, map) -> map reader)
|> join cTok.Token
let dataSource = dataGenerator source cTok.Token
do!
collapse dataSource [|pipe3D; pipeRedFilter; pipeBlueFilter; pipeGreenFilter|]
|> pipelineAction cTok.Token (fun imageInfo -> ImageProcessingHelpers.saveImage imageInfo)
}
In this code implementation, we are expanding the ForkJoin Pipeline to run concurrently different branches of the image processing workflow. Each branch applies different image processing concurrently fusing together the different stages using the “collapse” function, which creates a pair between the source of the data items with the different workflow branches.
let collapse (source: ChannelReader<'a>) (maps: (ChannelReader<'a> -> ChannelReader<'b>) array) =
let countBranches = maps |> Array.length
let sources = broadcast cTok.Token countBranches source
Array.zip sources maps
|> Array.map (fun (reader, map) -> map reader)
|> join cTok.Token
In the “collapse” function, the source of the data items is based on the “broadcast” function, which are fused together with the “join” function after their processing. The advantage of this design is that each branch of the workflow runs simultaneously with an independent and dedicated task that handles a copy of the data items produced from the initial stage.
I hope this brings you some merry coding and good cheer! Happy Holidays to you and your family, looking forward to wonderful new year with the vibrant F# community!